
For GPU enthusiasts, it's been a long wait. Nvidia kept the Turing line going for two years before replacing it with Ampere in September 2020. AMD were a little kinder, leaving a 15 month gap between their new designs, but most people weren't interested in that.
What they wanted to see was AMD launching a top end model to compete head-to-head with the best from Nvidia. They did just that and now that we've seen the results, PC gamers are now spoilt for choice (at least theoretically), when it comes to spending their dollars on the best performing graphics cards.
But what about the chips powering them? Is one of them fundamentally better than the other?
Read on to see how Ampere and RDNA 2 battle it out!
Article Index
- Nodes and die sizes
- Overall structure of Ampere GA102 and RDNA 2 Navi 21
- How everything is organized inside the chips
- Counting cores the Nvidia way
- Ray Tracing
- Memory system, multi-level caches
- Rendering pipelines, SAM, RTX IO
- Multimedia engine, streaming
- Built for compute, built for gaming
Nvidia shrinks, AMD grows
Nodes and die sizes
High-end GPUs have been considerably bigger than CPUs for a number of years, and they've been steadily increasing in size. AMD's latest offering is roughly 520 mm2 in area, more than double the size of their previous Navi chip. It's not their largest, though – that honor goes to the GPU in their new Instinct MI100 accelerator, at around 750 mm2.
The last time AMD made a gaming processor anywhere near the size of Navi 21 was for the Radeon R9 Fury and Nano cards, which sported the GCN 3.0 architecture in a Fiji chip. It was 596 mm2 in die area, but it was manufactured on TSMC's 28HP process node.
AMD has been using TSMC's much smaller N7 process since 2018 and the biggest chip from that production line was the Vega 20 (as found in the Radeon VII), with an area of 331 mm2. All of their Navi GPUs are made on a slightly updated version of that process, called N7P, so it makes to compare these products.

But when it comes to sheer die size, Nvidia takes the crown, not that this is necessarily a good thing. The latest Ampere-based chip, the GA102, is 628 mm2. That's actually about 17% smaller than its forefather, the TU102 – that GPU was a staggering 754 mm2 in die area.
Both pale in size when compared to Nvidia's monstrous GA100 chip - used in AI & data centers, this GPU is 826 mm2 and it's a TSMC N7 chip. While never designed to power a desktop graphics card, it does show what scale of GPU manufacturing is possible.
Putting them all side-by-side highlights just how bulky Nvidia's biggest GPUs are. The Navi 21 looks fairly svelte, although there's more to a processor than just die area. The GA102 is packing around 28.3 billion transistors, whereas AMD's new chip sports 5% fewer, at 26.8 billion.

What we don't know is how many layer each GPU is built of, so all we can compare is the ratio of transistors to die area, typically called die density. The Navi 21 is roughly 51.5 million transistors per square mm, but the GA102 is notably lower at 41.1 – it could be that Nvidia's chip is stacked a little higher than AMD's, but it's more likely to be an indication of process node.
As already mentioned, the Navi 21 is manufactured by TSMC, using their N7P production method, which offers a small increase in performance over N7; but for their new offering, the GA102, Nvidia turned to Samsung for production duties. The South Korea semiconductor giant is using a tweaked version, specifically for Nvidia, of their so-called 8 nm node (labelled as 8N or 8NN).
These node values, 7 and 8, have little to do with the actual size of the components with the chips: they're simply marketing terms, used to differentiate between the various production techniques. That said, even if the GA102 has more layers than the Navi 21, the die size does have one particular impact.

Microprocessors and other chips are fabricated from large, circular discs of highly refined silicon and other materials, called wafers. TSMC and Samsung use 300 mm wafers for AMD and Nvidia, and each disc will generate more chips using smaller dies compared to larger ones.
The difference is unlikely to be huge, but when every wafer costs thousands of dollars to produce, AMD have a small advantage over Nvidia, when it comes to keeping manufacturing costs down. That's assuming, of course, Samsung or TSMC aren't doing some kind of financial deal with AMD/Nvidia.
All of this die size and transistor count shenanigans would be for naught, if the chips themselves weren't any good at what they're design to do. So let's dig into the layouts of each new GPU and see what's underneath their hoods.
Dissecting the dies
Overall structure of Ampere GA102 and RDNA 2 Navi 21
We start our exploration of the architectures with a look at the overall structure of the Ampere GA102 and RDNA 2 Navi 21 GPUs – these diagrams don't necessarily show us how everything is physically laid out, but they give a clear indication as to how many components the processors have.
In both cases, the layouts are very familiar, as they are essentially expanded versions of their predecessors. Adding more units to process instructions will always increase the performance of a GPU, because at high resolutions in the latest 3D blockbusters, the rendering workloads involve a huge number of parallel calculations.

Such diagrams are useful, but for this particular analysis, it's actually more interesting looking at where the various components are within the GPU dies themselves. When designing a large scale processor, you generally want shared resources, such as controllers and cache in a central position, to ensure every component has the same path to them.
Interface systems, such as local memory controllers or video outputs, should go on the edges of the chip to make it easier to connect them to the thousands of individual wires that link the GPU to the rest of the graphics card.
Below are false-color images of AMD's Navi 21 and Nvidia's GA102 dies. Both have been run through some image processing to clean up the images, and both are really only showing one layer within the chip; but they do give us a superb view of the innards of a modern GPU.
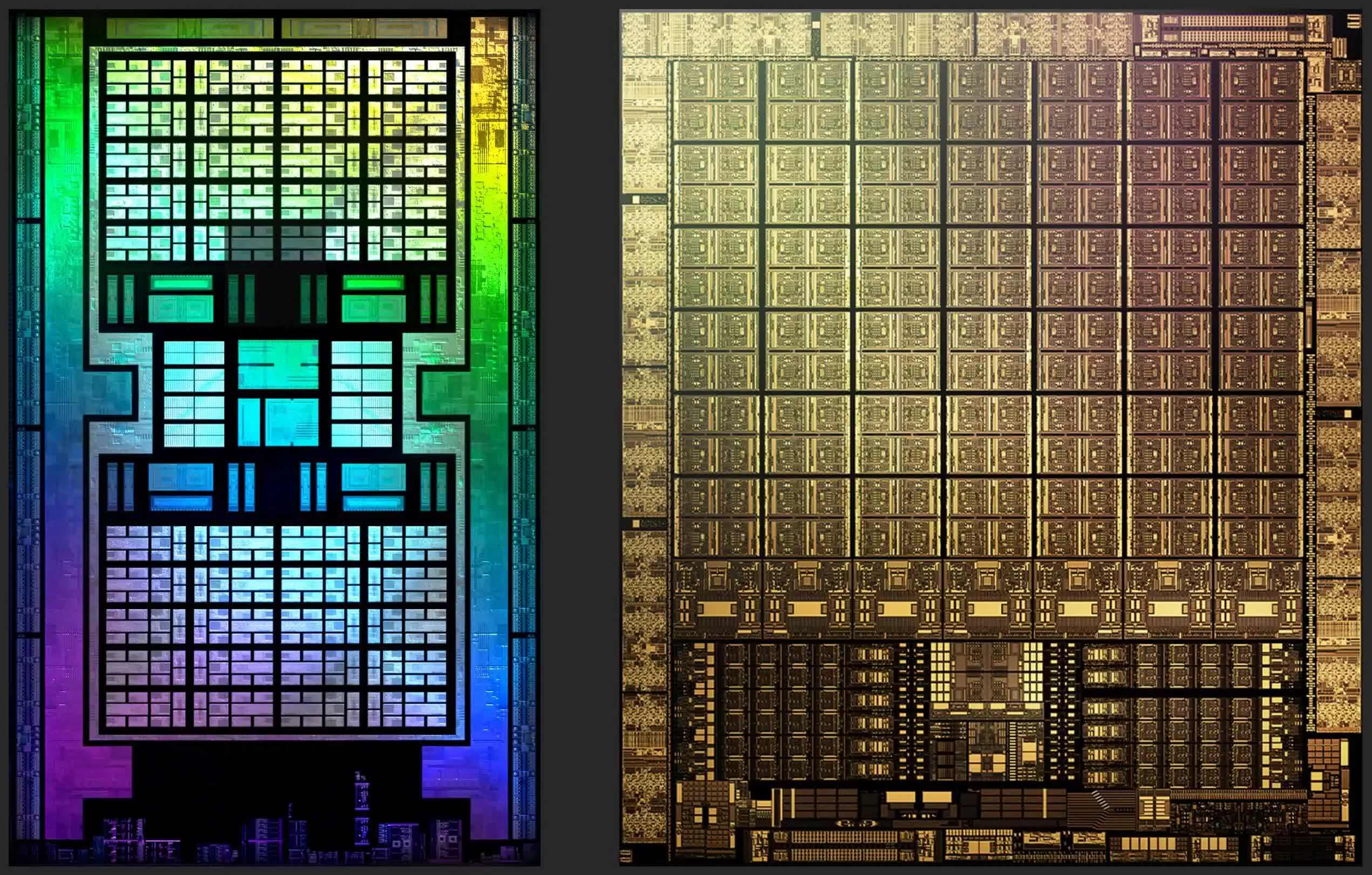
The most obvious difference between the designs is that Nvidia hasn't followed a centralized approach to the chip layout – all of the system controllers and main cache are at the bottom, with the logic units running in long columns. They've done this in the past, but only with middle/lower end models.
For example, the Pascal GP106 (used in the likes of the GeForce GTX 1060) was literally half of a GP104 (from the GeForce GTX 1070). The latter was the larger chip, and had its cache and controllers in the middle; these moved to the side in its sibling, but only because of the design had been split.

For all their previous top end GPU layouts, Nvidia used a classic centralized organization. So why the change here? It can't be for interface reasons, as the memory controllers and the PCI Express system all run around the edge of the die.
It won't be for thermal reasons either, because even if the cache/controller part of the die ran hotter than the logic sections, you'd still want it in the middle to have more silicon around it to help absorb and dissipate the heat. Although we're not totally sure of the reason for this change, we suspect that it's to do with the changes Nvidia have implemented with the ROP (render output) units in the chip.
We'll look at those in more detail later on, but for now let's just say that while the change in layout looks odd, it won't make a significant difference to performance. This is because 3D rendering is riddled with lots of long latencies, typically due to having to wait for data. So the additional nanoseconds added by having some logic units further from the cache than others, all get hidden in the grand scheme of things.
Before we move on, it's worth remarking on the engineering changes AMD implemented in the Navi 21 layout, compared to the Navi 10 that powered the likes of the Radeon RX 5700 XT. Even though the new chip is double the size, both in terms of area and transistor count, than the earlier one, the designers also managed to also improve the clock speeds, without significantly increasing power consumption.
For example, the Radeon RX 6800 XT sports a base clock and boost clock of 1825 and 2250 MHz respectively, for a TDP of 300 W; the same metrics for the Radeon RX 5700 XT were 1605 MHz, 1905 MHz, and 225 W. Nvidia raised the clock speeds with Ampere, too, but some of that can be attributed towards using a smaller and more efficient process node.

Our performance-per-watt examination of Ampere and RDNA 2 cards showed that both vendors have made significant improvements in this area, but AMD and TSMC have achieved something quite remarkable – compare the difference between the Radeon RX 6800 and the Radeon VII in the chart above.
The latter was their first GPU collaboration using the N7 node and in the space of less than two years, they've increased the performance-per-watt by 64%. It does beg the question as to how much better the Ampere GA102 could have been, had Nvidia stayed with TSMC for their production duties.
Managing a GPU factory
How everything is organized inside the chips
When it comes to the processing of instructions and managing data transfers, both Ampere and RDNA 2 follow a similar pattern to how everything is organized inside the chips. Game developers code their titles using a graphics API, to make all of the images; it might be Direct3D, OpenGL, or Vulkan. These are essentially software libraries, packed full of 'books' of rules, structures, and simplified instructions.
The drivers that AMD and Nvidia create for their chips essentially work as translators: converting the routines issued via the API into a sequence of operations that the GPUs can understand. After that, it's entirely down to the hardware to manage things, with regards to what instructions get done first, what part of the chip does them, and so on.
This initial stage of instruction management is handled by a collection of units, reasonably centralized in the chip. In RDNA 2, graphics and compute shaders are routed through separate pipelines, that schedule and dispatch the instructions to the rest of the chip; the former is called the Graphics Command Processor, the latter are Asynchronous Compute Engines (ACEs, for short).

Nvidia just uses one name to describe their set of management units, the GigaThread Engine, and in Ampere it does the same task as with RDNA 2, although Nvidia doesn't say too much about how it actually manages things. Altogether, these command processors function rather like a production manager of a factory.
GPUs get their performance from doing everything in parallel, so the next level of organization is duplicated across the chip. Sticking with the factory analogy, these would be akin to a business that has a central office, but multiple locations for the manufacturing of goods.
AMD uses the label Shader Engine (SE), whereas Nvidia calls theirs Graphics Processing Clusters (GPC) – different names, same role.

The reason for this partitioning of the chip is simple: the command processing units just can't handle everything, as it would end up being far too large and complex. So it makes sense to push some of the scheduling and organization duties further down the line. It also means each separation partition can be doing something completely independent of the others – so one could be handling a raft of graphics shaders, while the others are grinding through long, complex compute shaders.
In the case of RDNA 2, each SE contains its own set of fixed function units: circuits that are designed to do one specific task, that typically can't be heavily adjusted by a programmer.
- Primitive Setup unit – gets vertices ready for processing, as well as generating more (tessellation) and culling them
- Rasterizer – converts the 3D world of triangles into a 2D grid of pixels
- Render Outputs (ROPs) – reads, writes, and blends pixels
The primitive setup unit runs at a rate of 1 triangle per clock cycle. This might not sound like very much but don't forget that these chips are running at anywhere between 1.8 and 2.2 GHz, so primitive setup shouldn't ever be a bottleneck for the GPU. For Ampere, the primitive unit is found in the next tier of organization, and we'll cover that shortly.
Neither AMD nor Nvidia say too much about their rasterizers. The latter calls them Raster Engines, we know that they handle 1 triangle per clock cycle, and spit out a number of pixels, but there's no further information to hand, such as their sub-pixel precision, for example.
Each SE in the Navi 21 chip sports 4 banks of 8 ROPs, resulting in a total of 128 render output units; Nvidia's GA102 packs 2 banks of 8 ROPs per GPC, so the full chip sports 112 units. This might seem that AMD has the advantage here, because more ROPs means more pixels can be processed per clock. But such units need good access to cache and local memory, and we'll say more about that later in this article. For now, let's continue looking at how the SE/GPC partitions are further divided.

AMD's Shader Engines are sub-partitioned in what they term Dual Compute Units (DCUs), with the Navi 21 chip fielding ten DCUs per SE – note that in some documents, they're also classed as Workgroup Processors (WGP). In the case of Ampere and the GA102, they're called Texture Processing Clusters (TPCs), with each GPU containing 6 TPCs. Every cluster in Nvidia's design houses something called a Polymorph Engine – essentially, Ampere's primitive setup units.
They too run at a rate of 1 triangle per clock, and although Nvidia's GPUs are clocked lower than AMD's, they have a lot more TPCs than Navi 21 has SEs. So for the same clock speed, the GA102 should have a notable advantage as the complete chip holds 42 primitive setup units, whereas AMD's new RDNA 2 has just 4. But since there are six TPCs per Raster Engine, the GA102 effectively has 7 complete primitive systems, to the Navi 21's four. Since the latter isn't clocked 75% higher than the former, it would seem that Nvidia takes a clear lead here, when it comes to geometry handling (though no game is likely to be limited in this area).
The final tier of the chips' organization are the Compute Units (CUs) in RDNA 2 and the Streaming Multiprocessors (SMs) in Ampere – the production lines of our GPU factories.

These are very much the meat-and-vegetables in the GPU pie, as these hold all of the highly programmable units used to process graphics, compute, and now ray tracing shaders. As you can see in the above image, each one takes up a very small portion of the overall die space, but they are still extremely complex and highly important to the overall performance of the chip.
Up to now, there hasn't been any serious deal-breakers, when it comes to how everything is laid out and organized in the two GPUs – the nomenclature is all different, but their functions are much the same. And because so much of what they do is limited by programmability and flexibility, any advantages one has over the other, just comes down to a sense of scale, i.e. which one has the most of that particular thing.
But with the CUs and SMs, AMD and Nvidia take different approaches to how they go about processing shaders. In some areas, they share a lot in common, but there are plenty of others where that's not the case.
Counting cores the Nvidia way
Since Ampere ventured into the wild before RDNA 2, we'll take a look at Nvidia's SMs first. There's no point in looking at images of the die itself now, as they can't tell us exactly what's inside them, so let's use an organization diagram. These aren't supposed to be representations of how the various components are physically arranged in the chip, just how many of each type are present.
Where Turing was a substantial change to its desktop predecessor Pascal (losing a stack of FP64 units and registers, but gaining tensor cores and ray tracing), Ampere is actually a fairly mild update – on face value, at least. As far as Nvidia's marketing division was concerned, though, the new design more than doubled the number of CUDA cores in each SM.

In Turing, the Streaming Multiprocessors contain four partitions (sometimes called processing blocks), where each house 16x INT32 and 16x FP32 logic units. These circuits are designed to carry out very specific mathematical operations on 32-bit data values: the INT units handled integers, and the FP units worked on floating point, i.e. decimal, numbers.
Nvidia states that an Ampere SM has a total of 128 CUDA cores, but strictly speaking, this isn't true – or if we must stick to this count, then so too did Turing. The INT32 units in that chip could actually handle float values, but only in a very small number of simple operations. For Ampere, Nvidia has opened the range of floating point math operations they support to match the other FP32 units. That means the total number of CUDA cores per SM hasn't really changed; it's just that half of them now have more capability.
All of the cores in each SM partition processes the same instruction at any one time, but since the INT/FP units can operate independently, the Ampere SM can handle up to 128x FP32 calculations per cycle or 64x FP32 and 64x INT32 operations together. In Turing, it was just the latter.
So the new GPU has, potentially, double the FP32 output than its predecessor. For compute workloads, especially in professional applications, this is a big step forward; but for games, the benefits will be far more muted. This was evident when we first tested the GeForce RTX 3080, which uses a GA102 chip with 68 SMs enabled.

Despite having a peak FP32 throughput 121% over the GeForce 2080 Ti, it only averages a 31% increase in frame rates. So why is all that compute power going to waste? The simple answer is that it's not, but games aren't running FP32 instructions all the time.
When Nvidia released Turing in 2018, they pointed out that on average about a 36% of the instructions processed by a GPU involved INT32 routines. These calculations are typically run for working out memory addresses, comparisons between two values, and logic flow/control.

So for those operations, the dual rate FP32 feature doesn't come into play, as the units with the two data pathways can only do integer or floating point. And an SM partition will only switch to this mode if all 32 threads, being handled by it at the time, have the same FP32 operation lined up to be processed. In all other cases, the partitions in Ampere operate just as they do in Turing.
This means the likes of the GeForce RTX 3080 only has a 11% FP32 advantage over the 2080 Ti, when operating in INT+FP mode. This is why the actual performance increase seen in games isn't as high as the raw figures suggest it should be.
Other improvements? There are fewer Tensor Cores per SM partition, but each one is a lot more capable than those in Turing. These circuits perform a very specific calculations (such as multiply two FP16 values and accumulate the answer with another FP16 number), and each core now does 32 of these operations per cycle.

They also support a new feature called Fine-Grained Structured Sparsity and without going into the details of it all, essentially it means the math rate can be doubled, by pruning out data that doesn't affect the answer. Again, this is good news for professionals working with neural networks and AI, but at the moment, there's no significant benefit for game developers.
The ray tracing cores have also been tweaked: they can now work independently of the CUDA cores, so while they're doing BVH traversal or ray-primitive intersection math, the rest of the SM can still be processing shaders. The part of the RT Core that handles the testing of whether or not a ray intersects a primitive has doubled in performance, too.

The RT Cores also sport additional hardware to help apply ray tracing to motion blur, but this feature is currently only exposed through Nvidia's proprietary Optix API.
There are other tweaks, but the overall approach has been one of sensible but steady evolution, rather than a major new design. But given that there was nothing particularly wrong with Turing's raw capabilities in the first place, it's not surprising to see this.
So what about AMD – what have they done to the Compute Units in RDNA 2?
Tracing the rays fantastic
On face value, AMD haven't changed much about the Compute Units – they still contain two sets of an SIMD32 vector unit, an SISD scalar unit, textures units, and a stack of various caches. There's been some changes regarding what data types and associated math operations they can do, and we'll say more about those in a moment. The most notable change for the general consumer is that AMD now offer hardware acceleration for specific routines within ray tracing.
This part of the CU performs ray-box or ray-triangle intersection checks – the same as the RT Cores in Ampere. However, the latter also accelerates BVH traversal algorithms, whereas in RDNA 2 this is done via compute shaders using the SIMD 32 units.
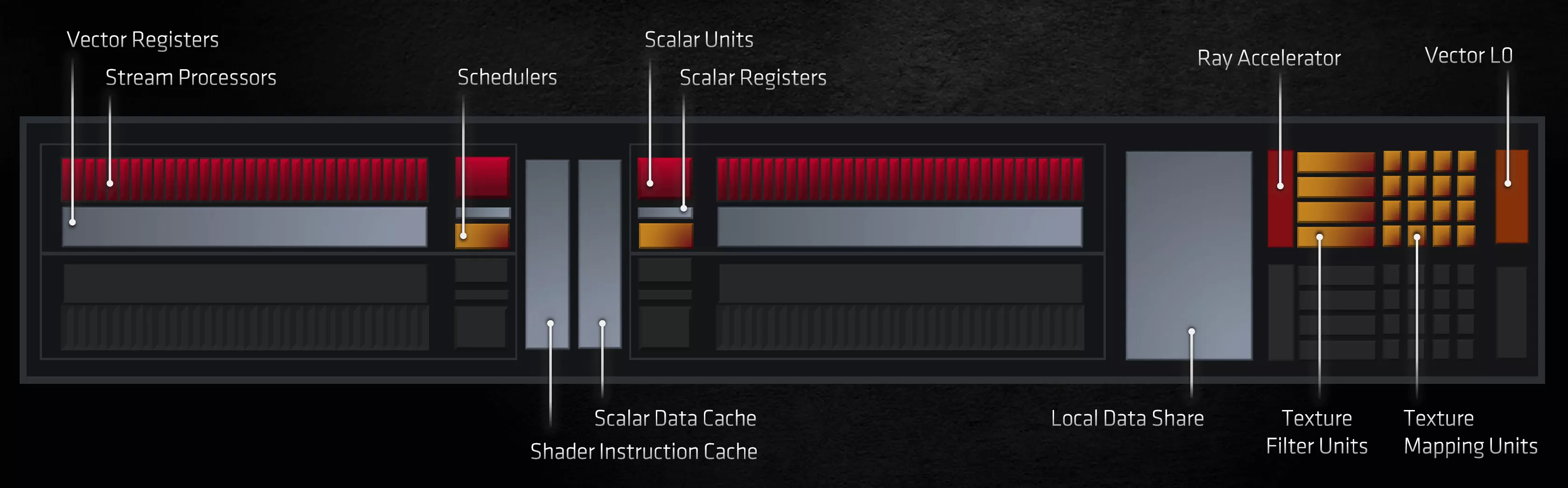
No matter how many shader cores one has or how high their clock rates are, going with customized circuits that are designed to do just one job is always going to be better than a generalized approach. This is why GPUs were invented in the first place: everything in the world of rendering can be done using a CPU, but their general nature makes them unsuitable for this.
The RA units are next to the texture processors, because they're actually part of the same structure. Back in July 2019, we reported on the appearance of a patent filed by AMD which detailed using a 'hybrid' approach to handling the key algorithms in ray tracing...
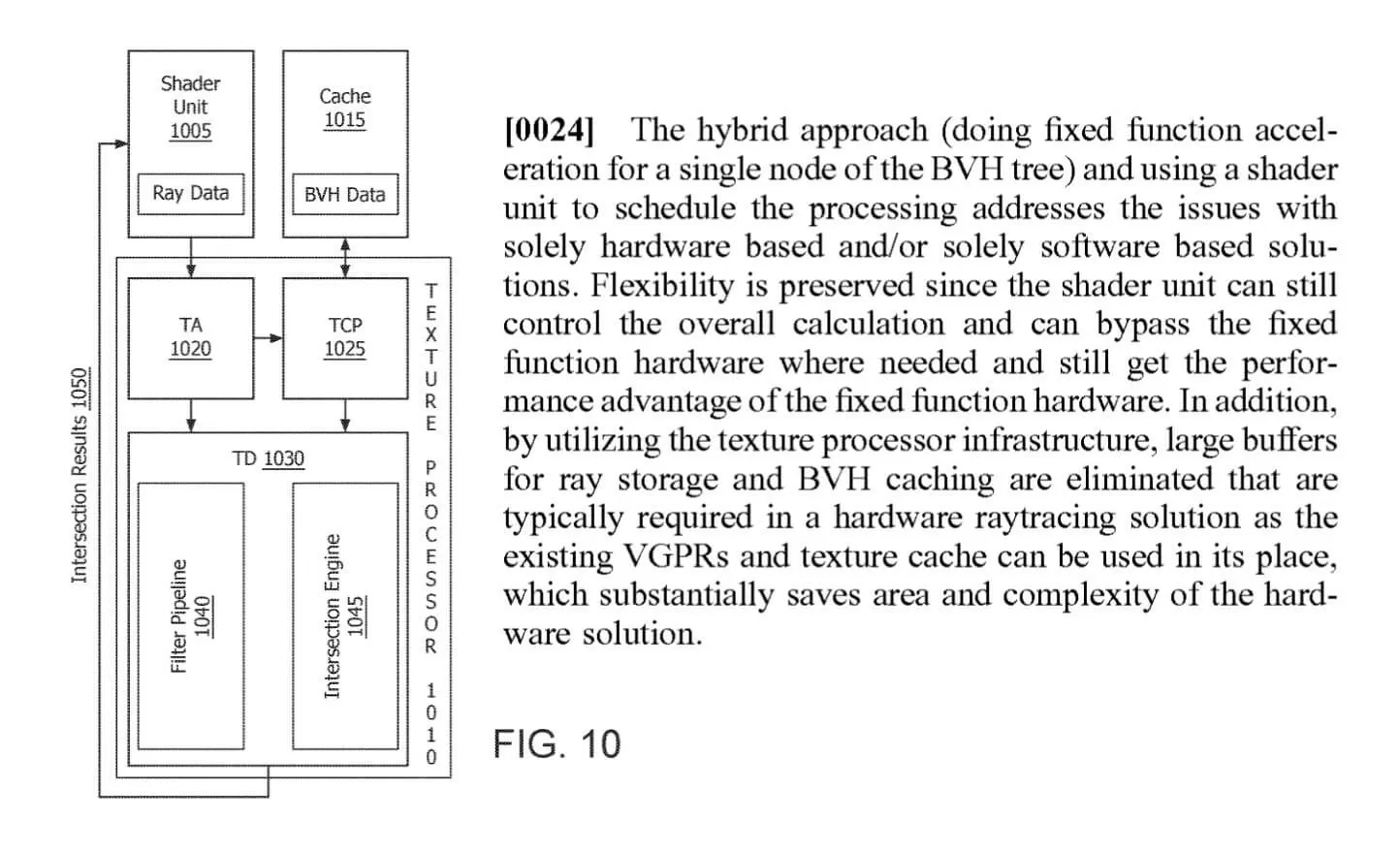
While this system does offer greater flexibility and removes the need to have portions of the die doing nothing when there's ray tracing workload, AMD's first implementation of this does have some drawbacks. The most notable of which is that the texture processors can only handle operations involving textures or ray-primitive intersections at any one time.
Given that Nvidia's RT Cores now operate fully independently of the rest of the SM, this would seem to give Ampere a distinct lead, compared to RNDA 2, when it comes to grinding through the acceleration structures and intersection tests required in ray tracing.
Although we've only briefly examined the ray tracing performance in AMD's latest graphics cards, so far we did find that the impact of the use of ray tracing was very dependent on the game being played.

In Gears 5, for example, the Radeon RX 6800 (which uses a 60 CU variant of the Navi 21 GPU) only took a 17% frame rate hit, whereas in Shadow of the Tomb Raider, this rose to an average loss of 52%. In comparison, Nvidia's RTX 3080 (using a 68 SM GA102) saw average frame rate losses of 23% and 40% respectively, in the two games.
A more detailed analysis of ray tracing is needed to say anything more about AMD's implementation, but as a first iteration of the technology, it does appear to be competitive but sensitive to what application is doing the ray tracing.
As previously mentioned, the Compute Units in RDNA 2 now support more data types; the most notable inclusions are the low precision data types such as INT4 and INT8. These are used for tensor operations in machine learning algorithms and while AMD have a separate architecture (CDNA) for AI and data centers, this update is for use with DirectML.

This API is a recent addition to Microsoft's DirectX 12 family and the combination of hardware and software will provide better acceleration for denoising in ray tracing and temporal upscaling algorithms. In the case of the latter, Nvidia have their own, of course, called DLSS. Their system uses the Tensor Cores in the SM to perform part of the calculations, but given that a similar process can be constructed via DirectML, it might seem that these units are somewhat redundant. However, in both Turing and Ampere, the Tensor Cores also handle all math operations involving FP16 data formats.
With RDNA 2, such calculations are done using the shader units, using packed data formats, i.e. each 32-bit vector register holds two 16-bit ones. So which is the better approach? AMD labels their SIMD32 units as vector processors, because they issue one instruction for multiple data values.
Each vector unit contains 32 Stream Processors, and since each one of these just works on a single piece of data, the actual operations themselves are scalar in nature. This is essentially the same as an SM partition in Ampere, where each processing block also carries one instruction on 32 data values.
But where a entire SM in Nvidia's design can process up to 128 FP32 FMA calculations per cycle (fused multiply-add), a single RDNA 2 Compute Unit only does 64. Using FP16 raises this to 128 FMA per cycle, which is the same as Ampere's Tensor Cores when doing standard FP16 math.
Nvidia's SMs can process instructions to handle integer and float values at the same time (e.g. 64 FP32 and 64 INT32), and has independent units for FP16 operations, tensor math, and ray tracing routines. AMD's CUs do the majority of the workload on the SIMD32 units, although they do have separate scalar units that support simple integer math.
So it would seem that Ampere has the edge here: the GA102 has more SMs than Navi 21 has CUs, and they're packing a bigger punch, when it comes to peak throughput, flexibility, and features on offer. But AMD has a rather nice trick card up their sleeve.
Feeding those hungry hungry hippos
Memory system, multi-level caches
Having a GPU with thousands of logic units, all blazing their way through fancy math, is all well and good – but they'd be floundering at sea if they couldn't be fed quickly enough, with the instructions and data they require. Both designs sport a wealth of multi-level caches, boasting huge amounts of bandwidth.
Let's take a look at Ampere's first. Overall there have been some notable changes internally. The amount of Level 2 cache has increased by 50% (the Turing TU102 sported 4096 kB respectively), and the Level 1 caches in each SM have both doubled in size.

As before, Ampere's L1 caches are configurable, in terms of how much cache space can be allocated for data, textures, or general compute use. However, for graphics shaders (e.g. vertex, pixel) and asynchronous compute, the cache is actually set to:
- 64 kB for data and textures
- 48 kB for shared general memory
- 16 kB reserved for specific operations
Only when running in full compute mode, does the L1 become fully configurable. On the plus side, the amount of bandwidth available has also doubled, as the cache can now read/write 128 bytes per clock (although there's no word on whether or not the latency has been improved, too).
The rest of the internal memory system has remained the same in Ampere, but when we move just outside the GPU, there's a nice surprise in store for us. Nvidia partnered with Micron, a DRAM manufacturer, to use a modified version of GDDR6 for their local memory needs. This is still essentially GDDR6 but the data bus has been entirely replaced. Rather than using a conventional 1 bit per pin set up, where the signal just bounces very rapidly between two voltages (aka PAM), GDDR6X uses four voltages:

With this change, GDDR6X effectively transfers 2 bits of data per pin, per cycle – so for the same clock speed and pin count, the bandwidth is doubled. The GeForce RTX 3090 sports 24 GDDR6X modules, running in single channel mode and rated to 19 Gbps, giving a peak transfer bandwidth of 936 GB/s.
That's an increase of 52% over the GeForce RTX 2080 Ti and not something to be dismissed lightly. Such bandwidth figures have only been achieved in the past by using the likes of HBM2, which can be costly to implement, when compared to GDDR6.
However, only Micron makes this memory and the use of PAM4 adds additional complexity to the production process, requiring far tighter tolerances with the signalling. AMD went down a different route – instead of turning to an outside agency for help, they used their CPU division to bring something new to the table. The overall memory system in RDNA 2 hasn't changed much compared to its predecessor – there are only two major changes.

Each Shader Engine now has two sets of Level 1 caches, but as they are now sporting two banks of Dual Compute Units (RDNA just had the one), this alteration is to be expected. But shoehorning 128 MB of Level 3 cache into the GPU? That surprised a lot of people. Utilizing the SRAM design for the L3 cache found in their EPYC-range of Zen 2 server chips, AMD have embedded two sets of 64 MB high-density cache into the chip. Data transactions are handled by 16 sets of interfaces, each shifting 64 bytes per clock cycle.
The so-called Infinity Cache has its own clock domain, and can run at up 1.94 GHz, giving a peak internal transfer bandwidth of 1986.6 GB/s. And because it's not external DRAM, the latencies involved are exceptionally low. Such cache is perfect for storing ray tracing acceleration structures and since BVH traversal involves a lot of data checking, the Infinity Cache should notably help with this.

At the moment, it's not clear if the Level 3 cache in RDNA 2 operates in the same way as in a Zen 2 CPU: i.e. as a Level 2 victim cache. Normally, when the last level of cache needs to be cleared to make room for new data, any new requests for that information will have to go to the DRAM.
A victim cache stores data that's been flagged for removal from the next tier of memory, and with 128 MB of it to hand, the Infinity Cache could potentially store 32 complete sets of L2 cache. This system results in less demand being placed on the GDDR6 controllers and DRAM.
Older GPU designs by AMD have struggled with a lack of internal bandwidth, especially as once their clock speeds were ramped up, but the extra cache will go a long way to making this issue fade into the background.

So which design is better here? The use of GDDR6X gives the GA102 enormous bandwidth to the local memory, and the larger caches will help reduce the impact of cache misses (which stall the processing of a thread). Navi 21's massive Level 3 cache means the DRAM doesn't have to tapped as often, and leverages the ability to run the GPU at higher clock speeds without data starvation.
AMD's decision to stick with GDDR6 means there are more sources of memory available for third party vendors, meanwhile any company making a GeForce RTX 3080 or 3090 will have to use Micron. And while GDDR6 comes in a variety of modules densities, GDDR6X is currently limited to 8 Gb.
The cache system within RDNA 2 is arguably a better approach than that used in Ampere, as using multiple levels of on-die SRAM will always provide lower latencies, and better performance for a given power envelope, than external DRAM, regardless of the latter's bandwidth.
The ins and outs of a GPU
Rendering pipelines
Both architectures feature a raft of updates to the front and back ends of their rendering pipelines. Ampere and RDNA 2 fully sport mesh shaders and variable rate shaders in DirectX12 Ultimate, although Nvidia's chip does have more geometry performance thanks to its greater number of processors for these tasks.
While the use of mesh shaders will enable developers to create ever more realistic environments, no game is ever going to have its performance be entirely bound to this stage in the rendering process. This is because the bulk of the hardest work is at the pixel or ray tracing stages.

This is where the use of variable rate shaders come into play – basically, the process involves apply shaders for lighting and color on a block of pixels, rather than individual ones. It's akin to decreasing the resolution of the game in order to improve performance, but since it can be applied to just selected regions, the loss in visual quality isn't readily apparent.
But both architectures have also been given an update to their render output units (ROPs), as this will improve performance at high resolutions, whether or not variable rate shaders are used. In all previous generations of their GPUs, Nvidia tied the ROPs to the memory controllers and Level 2 cache.
In Turing, eight ROP units (collectively called a partition) were directly linked to one controller and a 512 kB slice of the cache. Adding more ROPs creates a problem, as it requires more controllers and cache, so for Ampere, the ROPs are now entirely allocated to a GPC. The GA102 sports 12 ROPs per GPC (each one processing 1 pixel per clock cycle), giving a total of 112 units for the full chip.
AMD follows a similar system to Nvidia's old approach (i.e. tied to a memory controller and L2 cache slice), although their ROPs are primarily use the Level 1 cache for pixel read/writes and blending. In the Navi 21 chip, they've been given a much needed update and each ROP partition now handles 8 pixels per cycle in 32-bit color, and 4 pixels in 64-bit.
Something else that Nvidia have brought to the table with Ampere is RTX IO – a data handling system that allows the GPU to directly access the storage drive, copy across the data it needs, and then decompress it using the CUDA cores. At the moment, though, the system can't be used in any game, because Nvidia are using the DirectStorage API (another DirectX12 enhancement) to control it and that's not ready for public release yet.

The methods used at the moment involve having the CPU manage all this: it receives the data request from the GPU drivers, copies the data from the storage drive to the system memory, decompresses it, and then copies it across to the graphics card's DRAM.
Besides the fact that this involves a lot of wasted copying, the mechanism is serial in nature – the CPU processes one request at a time. Nvidia are claiming figures such as "100x data throughput" and "20x lower CPU utilization," but until the system can be tested in the real world, such figures can't be examined further.

When AMD introduced RDNA 2 and the new Radeon RX 6000 graphics cards, they launched something called Smart Access Memory. This is not their answer to Nvidia's RTX IO – in fact, it's not even really a new feature. By default, the PCI Express controller in the CPU can address up to 256 MB of the graphics card's memory, per individual access request.
This value is set by the size of the base address register (BAR) and as far back as 2008, there has been an optional feature in the PCI Express 2.0 specification to allow it be resized. The benefit of this is that fewer access requests have to be processed in order to address the whole of the card's DRAM.
The function requires support by the operating system, CPU, motherboard, GPU, and its drivers. At present, on Windows PCs, the system is limited to a specific combination of Ryzen 5000 CPUs, 500 series motherboards, and Radeon RX 6000 graphics cards.

This simple feature gave some startling results when we tested it – performance boosts of 15% at 4K are not to be dismissed lightly, so it should come as no surprise that Nvidia have said that they'll be offering the feature for the RTX 3000 range at some point in the near future.
Whether or not resizable BAR support is rolled out for other platform combinations remains to be seen, but its use is certainly welcome, even though it's not an architectural feature of Ampere/RDNA 2 as such.
Video killed the radio star
Multimedia engine, video output
The GPU world is normally dominated by core count, TFLOPS, GB/s, and other headline-grabbing metrics, but thanks to the rise of YouTube content creators and live gaming streams, the display and multimedia engine capabilities are also of considerable note.
The demand for ultra high refresh rates, at all resolutions, has grown as the price of monitors supporting such features has dropped. Two years ago, a 144 Hz 4K 27" HDR monitor would have set you back $2,000; today, you can get something similar for almost half the price.
Both architectures provide a display output via HDMI 2.1 and DisplayPort 1.4a. The former offers more signal bandwidth, but they're both rated for 4K at 240 Hz with HDR and 8K at 60 Hz. This is achieved by using either 4:2:0 chroma subsampling or DSC 1.2a. These are video signal compression algorithms, which provide a significant reduction in bandwidth requirements, without too much loss of visual quality. Without them, even HDMI 2.1's peak bandwidth of 6 GB/s wouldn't be enough to transmit 4K images at a rate of 6 Hz.

Ampere and RDNA 2 also support variable refresh rate systems (FreeSync for AMD, G-Sync for Nvidia) and when it comes to the encoding and decoding of video signals, there's no discernable difference here either.
No matter which processor you look at, you'll find support for 8K AV1, 4K H.264, and 8K H.265 decoding, although exactly how well they both perform in such situations hasn't been thoroughly examined yet. Neither company gives much detail about the actual innards of their display and multimedia engines. As important as they are these days, it's still the rest of the GPU that garners all of the attention.
Different strokes for different folks
Built for compute, built for gaming
Enthusiasts of GPU history will know that AMD and Nvidia used to take rather different approaches to their architectural choices and configurations. But as 3D graphics have become increasingly dominated by the compute world and the homogenization of APIs, their overall designs have been increasingly similar.
And rather than the demands of rendering in today's games setting the tone for the architectures, it's the market sectors that the GPU industry has expanded into that's steering the direction. At the time of writing, Nvidia has three chips using the Ampere technology: the GA100, GA102, and GA104.

The last one is simply a cut-down version of the GA102 – it simply has fewer TPCs per GPC (and one less GPU overall) and two thirds the Level 2 cache. Everything else is exactly the same. The GA100, on the other hand, is a different beast altogether.
It has no RT Cores and no CUDA cores with INT32+FP32 support; instead it packs in a raft of additional FP64 units, more load/store systems, and an enormous amount of L1/L2 cache. It also has no display or multimedia engine whatsoever; this is because it's designed entirely for large scale compute clusters for AI and data analytics.
The GA102/104, though, need to cover every other market that Nvidia targets: gaming enthusiasts, professional graphics artists and engineers, and small scale AI and compute work. Ampere needs to be a 'jack of all trades' and a master of all of them – no easy task.

RDNA 2 was designed for just gaming, in PCs and consoles, although it could just as well turn its hand to the same areas as Ampere sells in. However, AMD chose to keep their GCN architecture going and update it for the demands of today's professional clients.
Where RDNA 2 has spawned 'Big Navi', CDNA could be said to have spawned 'Big Vega' - the Instinct MI100 houses their Arcturus chip, a 50 billion transistor GPU that sports 128 Compute Units. And like Nvidia's GA100, it too contains no display nor multimedia engines.
Although Nvidia heavily dominates the professional market with Quadro and Tesla models, the likes of the Navi 21 simply are not aimed at competing against these and has been designed accordingly. So does that make RDNA 2 the better architecture; does the requirement for Ampere to fit into multiple markets constrain it in any way?
When you look at the evidence, the answer would appear to be: no.

AMD will be releasing the Radeon RX 6900 XT soon, which uses a complete Navi 21 (no CUs disabled), which may perform as well as the GeForce RTX 3090 or better. But the GA102 in that card isn't fully enabled either, so Nvidia always have the option to update that model with a 'Super' version, as they did with Turing last year.
It could be argued that because RDNA 2 is being used in the Xbox Series X/S and PlayStation 5, game developers are going to favor that architecture will their game engines. But you only have to look at when GCN was used in the Xbox One and PlayStation 4 to see how this is likely to play out.
The first release of the former, in 2013, used a GPU built around the GCN 1.0 architecture – a design that didn't appear in desktop PC graphics cards until the following year. The Xbox One X, released in 2017, used GCN 2.0, a mature design was already over 3 years old by then.

So did all games made for the Xbox One or PS4 that got ported over to the PC automatically run better on AMD graphics cards? They did not. So we can't assume that this time will be different with RDNA 2, despite its impressive feature set.
But none of this ultimately matters, as both GPU designs are exceptionally capable and marvels of what can be achieved in semiconductor fabrication. Nvidia and AMD bring different tools to the bench, because they're trying to crack different problems; Ampere aims to be all things to all people, RDNA 2 is mostly about gaming.
This time round, the battle has drawn to a stalemate, even though each can claim victory in a specific area or two. The GPU wars will continue throughout next year, and a new combatant will enter the fray: Intel, with their Xe series of chips. At least we won't have to wait another two years to see how that fight runs its course!